BBoxDB Documentation
![]()
Documentation
Welcome to the documentation of BBoxDB. BBoxDB is a distributed NoSQL database which is optimized for the handling of multi-dimensional big data. In addition to stored data, also multi-dimensional data streams (e.g., data streams of position data) are supported by the software. Operations such as (continuous) range queries or (continuous) spatial joins are supported.
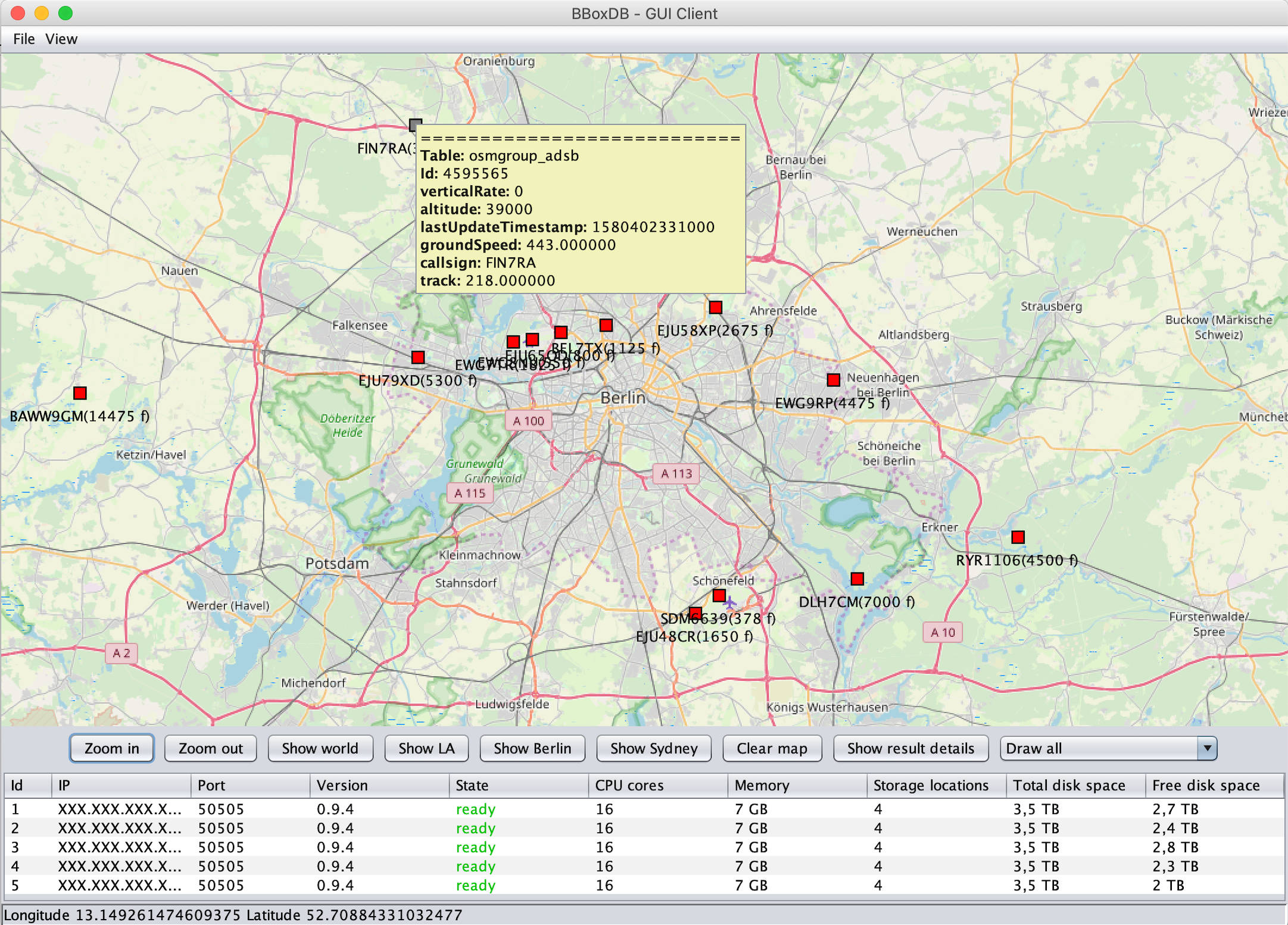
A continuous range query on a ADS-B datastream (aircraft position data)
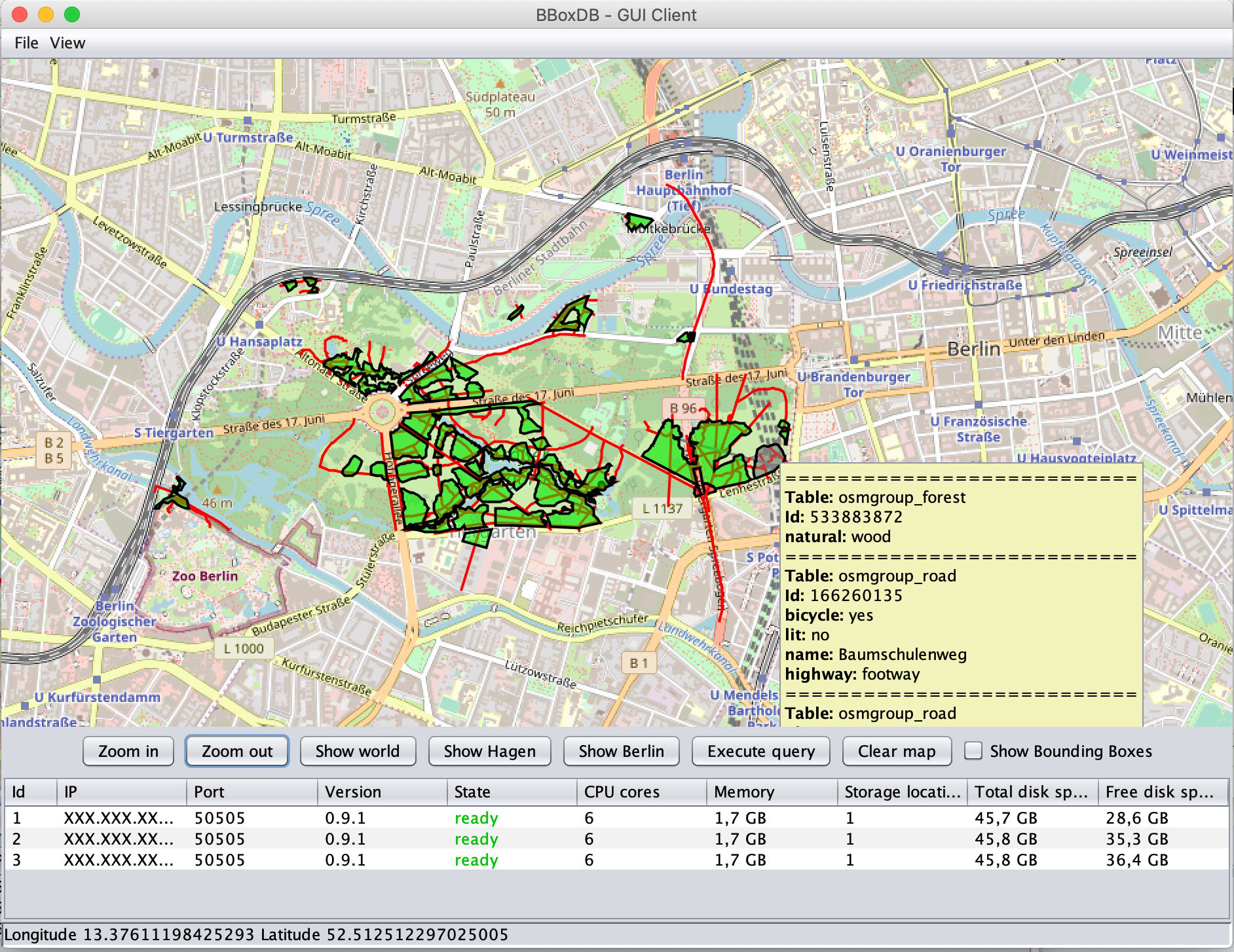
A spatial join between roads and forests on OpenStreetMap data
In contrast to traditional key-value stores, BBoxDB is optimized to handle multi-dimensional data. Stored data is placed into an n-dimensional space. The space is partitioned and assigned to the nodes of a cluster. SSTables (string sorted tables) are used as data storage. Apache Zookeeper is used to coordinate the whole system. The system can be accessed, using a network protocol. Some special features like continuous queries or a history for tuples are also supported.
Multi-dimensional data in regular key-value-stores
Existing key-value stores are using one-dimensional keys to address the values. Finding a proper key for multi-dimensional data is hard and often impossible; this is especially true when the data has an extent (e.g., regions). To retrieve multi-dimensional data from a key-value store, a full data scan is often required. BBoxDB was developed to avoid the expensive full data scan and to make the work with multi-dimensional data more convenient.
What is the difference between BBoxDB and regular key-value-stores?
NoSQL databases and especially key-value stores are very popular these days. They have a simple data model and can be easily implemented as a distributed system to handle big data. Techniques like hash- or range-partitioning are used to spread the data across a cluster of nodes. Each node stores only a small part of the whole dataset.
Key-value stores are using the key to retrieve the data. When the key is known, the data can be accessed easily. When the key for a value is not known, a complete scan of the data has to be carried out. Each value has to be loaded and tested if it matches the search criteria. This is a very expensive operation that should be avoided in any case.
Using the key to locate the data works well with one-dimensional data, but it becomes problematic when multi-dimensional data has to be stored. Its hard to find a proper key for a multi-dimensional value.
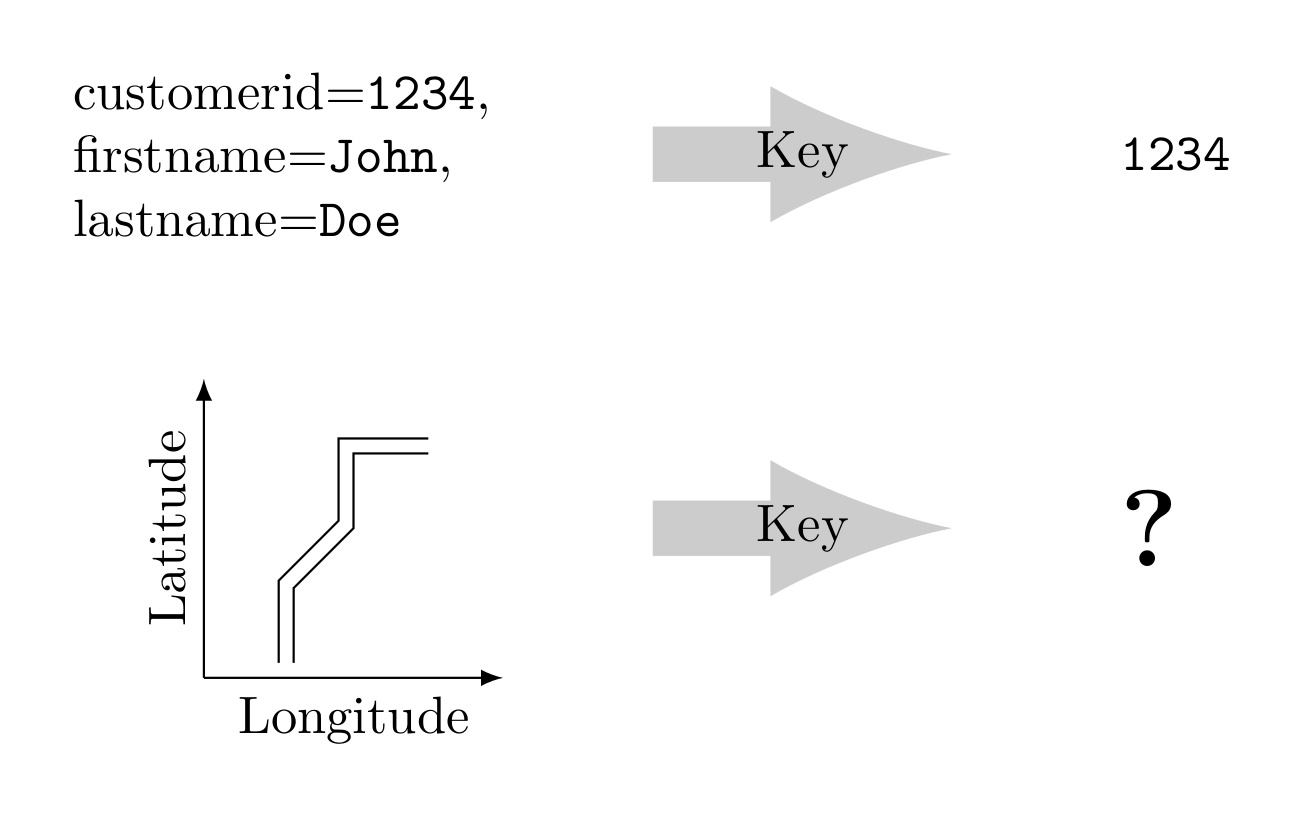
Example with one-dimensional data: Imagine that you have an online shop and you want to store all of your customers in a key-value store. A customer record has attributes like a customer id, a first name and a last name. To keep the example simple, we assume that the customer records are only accessed using the customer id attribute. Therefore, the records of the customers could be managed efficiently in a key-value store using the customer id attribute as key and the full customer record as value.
When the customer logs in to your online shop with his customer id, you can simply retrieve the full customer record from the key-value store by knowing the customer id.
Example with two-dimensional data: When you store the geographical information about a road, which key should you choose for the record? You can use the name of the road (e.g., road 66). However, this type of key does not help you to retrieve the road by knowing its coordinates. If you have a certain point in space and want to know which roads are located there, you have to perform a full data scan.
It is almost impossible to find a suitable key that allows locating multi-dimensional data efficiently. Existing techniques like linearization using a Z-Curve could encode multiple-dimensions into a one-dimensional key. Point data can be handled, but data with an extent (e.g., a road) is hard to handle. This is the reason why BBoxDB was developed.
BBoxDB extends the simple key-value data model; each value is stored together with a key and a bounding box. This is the reason why BBoxDB is called a key-bounding-box-value store. The bounding box describes the location of the data in an n-dimensional space. A space partitioner (a KD-Tree, a Quad-Tree or a Grid) is responsible to partition the whole space into partitions (distribution regions) and assign these regions to nodes in the cluster. Depending on the used space partitioner, the regions are split and merged dynamically (scale up and scale down), according to the amount of stored data. Point data and data which an extent (regions) of any dimension are supported by BBoxDB.
Hyperrectangle queries (range queries) can be efficiently handled by BBoxDB. This type of query is backed by a two-level index structure. Besides, BBoxDB can store tables with the same dimensions co-partitioned, this means that the data of the same regions in space are stored on the same nodes. Equi- and spatial-joins can be processed efficiently locally on co-partitioned data. No data shuffling is needed during query processing.
BBoxDB is implemented as a distributed and highly available system. It supports the available and partiotion tollerance aspects of the CAP theorem. SSTables (string sorted tables) are used as data storage. Apache Zookeeper is used to coordinate the whole system. Some special features like continuous queries or a history for tuples are also supported.