Datasets
OpenStreetMap
The Protocolbuffer Binary Format (.osm.pbf) format, used by OpenStreetMap, is not directly supported by BBoxDB. BBoxDB ships with an converter for .osm.pbf data to GeoJSON data. The converter reads .osm.pbf files, filters certain elements and writes the matching elements to separate files in GeoJSON format.
Internal architecture
.osm.pbf files consist of three different structures: nodes, ways, and relations. Nodes are simply points in the space; ways have an extend and are composed of multiple nodes. Relations describe the relationship between some nodes. The converter considers only nodes and ways. All structures are enhanced with properties; i.e., a key-value map, which contains information about the object. For example the name of the object or the maximal speed for a road.
The main task of the converter is to find all required nodes for the ways. The .osm.pbf files contain all nodes at the top; the ways are stored at the bottom of the files. The files are processed in a streaming manner with the Osmosis parser. Filters are applied to the nodes and ways. If the filter matches, the node or way is written into the appropriate output file in GeoJSON format.
At the moment, the converter filters the following nodes and ways:
| Filter | Content |
|---|---|
| BUILDING | All Buildings |
| ROAD | All Roads (road, route, way, or thoroughfare) |
| TRAFFIC_SIGNAL | All Traffic signals (also known as traffic lights) |
| TREE | All valuable trees |
| WATER | All lakes, ponds, rivers, canals, … |
| WOOD | All woods |
Nodes are also stored in a Berkeley DB database. Ways are consisting of multiple nodes. Before a way can be written into the output file, the corresponding nodes are fetched from the database (see Figure 1).
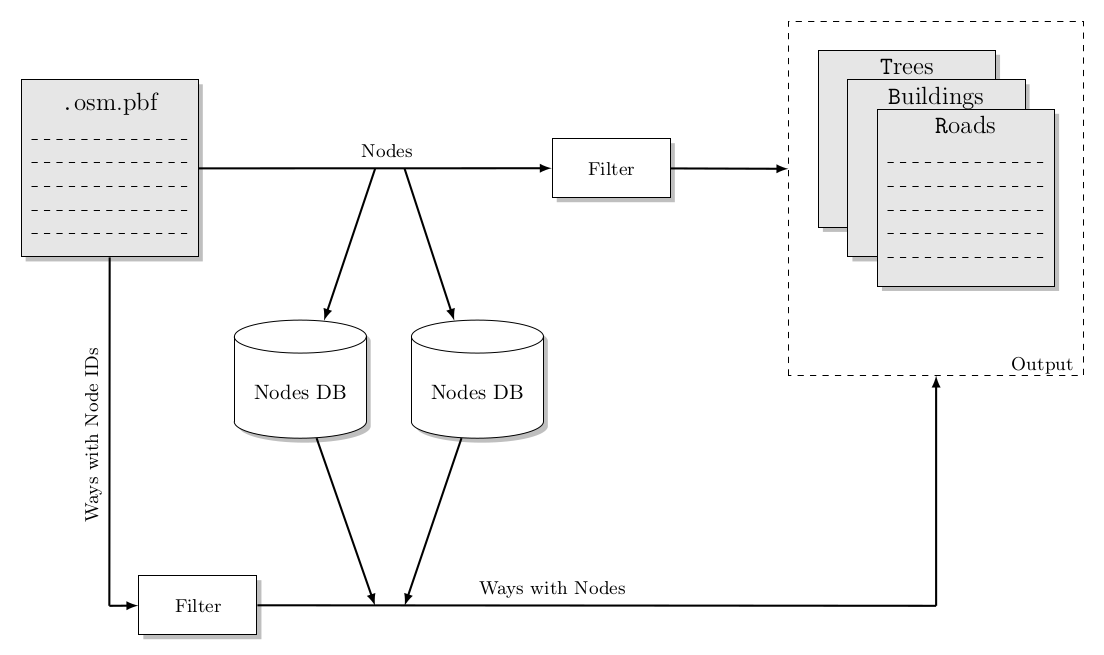
Figure 1: The architecture of the Converter. The .osm.pbf input file is read. Nodes are stored in one or more databases, filtered and written to the output files. Ways are filtered, the associated nodes are fetched from the database, and integrated in the way. Afterward, the new way object is written to the output files.
Usage
The converter requires three parameters, the input file, the folder(s) for the node databases and the output directory.
$ $BBOXDB_HOME/bin/osm_data_converter.sh
usage: OSMConverter
OpenStreetMap data converter
-backend <[jdbc_h2,jdbc_derby,bdb,sstable]> The node converter backend
-help Show this help
-input <file> The input file
-output <directory> The output directory
-workfolder <workfolder1:workfolder2:workfolderN> The working folder for the database
Please report issues at https://github.com/jnidzwetzki/bboxdb/issues
When the system consists of multiple hard disks, it is recommended to place the input and the output files on one disk and let the other disks store the node databases. It is also recommended, to increase the size of the ‘memory allocation pool’ of the JVM. The memory will be used as a cache for the databases and reduce the amount disk IO.
The converter supports different database backends to store the nodes. At the moment, the following backends are available:
| Backend | Name | Description |
|---|---|---|
| JDBC | jdbc_h2 | A backend using the h2 embedded database via JDBC |
| JDBC | jdbc_derby | A backend using the Apache Derby embedded database via JDBC |
| BDB | bdb | A backend using the Berkeley DB (Java edition) |
| SSTable | sstable | A backend using the the BBoxDB SSTables implementation |
In the following example, an extract of the OpenStreepMap database is downloaded and processed. It is assumed, that the system contains have four hard disks. One hard disk is used to store the input and the output data. The three remaining disks (mounted at /diskb, /diskc and /diskd) are used to store the Berkeley DB databases. If your system contains a huge amount of RAM (> 8 GB), you could adjust the jvm_ops_tools variable in bin/bboxdb-env.sh.
$ wget http://download.geofabrik.de/europe/germany-latest.osm.pbf
$ cd $BBOXDB_HOME
$ bin/osm_data_converter.sh -input /path/to/germany-latest.osm.pbf -backend bdb -workfolder /diskb/work:/diskc/work:/diskd/work -output /outputdir/germany
Example output
One line of the BUILDING file:
{"geometry":{"coordinates":[[49.485530000000004,8.905184100000001],[49.4855414,8.905173300000001],[49.485554500000006,8.9051691],[49.485567800000005,8.905171900000001],[49.4855797,8.9051814],[49.4855888,8.905196400000001],[49.4855941,8.9052153],[49.485595100000005,8.905235900000001],[49.4855918,8.9052545],[49.485584900000006,8.9052707],[49.485575000000004,8.9052827],[49.4855632,8.9052892],[49.4855506,8.9052897],[49.485538600000005,8.905284],[49.485528300000006,8.9052728],[49.485520900000004,8.905257200000001],[49.485517,8.905238800000001],[49.4855171,8.9052194],[49.485521600000006,8.9052],[49.485530000000004,8.905184100000001]],"type":"Polygon"},"id":481878096,"type":"Feature","properties":{"man_made":"silo","building":"yes"}}
One line of the ROAD file:
{"geometry":{"coordinates":[48.1763357,11.427178000000001],"type":"Point"},"id":128963,"type":"Feature","properties":{"ref":"7","TMC:cid_58:tabcd_1:LCLversion":"8.00","TMC:cid_58:tabcd_1:NextLocationCode":"31512","name":"München-Lochhausen","TMC:cid_58:tabcd_1:LocationCode":"31954","highway":"motorway_junction","TMC:cid_58:tabcd_1:PrevLocationCode":"42385","TMC:cid_58:tabcd_1:Class":"Point","TMC:cid_58:tabcd_1:Direction":"negative"}}
One line of the TREE file:
{"geometry":{"coordinates":[52.9744383,8.630228],"type":"Point"},"id":31339954,"type":"Feature","properties":{"natural":"tree"}}
Synthetic data
BBoxDB contains a generator for synthetic test data. Data with any desired length and bounding boxes in any desired dimension can be generated; the bounding box can be constructed as a point or a range in the specified dimension. The converter can be started with the following command:
$ $BBOXDB_HOME/bin/osm_data_converter.sh
usage: SyntheticDataGenerator
Synthetic data generator
-bboxtype <range|point> The type of the bounding box
-dimension <dimension> The dimension of the bounding box
-help Show this help
-lines <lines> The lines of tuples to produce
-outputfile <file> The outputfile
-size <size> The size in byte per tuple
Please report issues at https://github.com/jnidzwetzki/bboxdb/issues
The number of lines (parameter -lines), the dimension (parameter -dimension), the size of each line (parameter -size), the type of the bounding box (parameter -bboxtype) and the output file (parameter -outputfile) needs to be specified.
For example, 1,000,000 lines of 4-dimensional range data with 10 KB long lines can be generated with the following command:
$ $BBOXDB_HOME/bin/generate_synthetic_data.sh -amount 1000000 -size 10000 -dimension 4 -outputfile ~/datasets/synthetic/data.dat -bboxtype range
After the data set is generated, the output file contains lines like these:
42.2343,94.4312,80.8932,96.4278,46.2884,74.7693,65.7608,88.2144 u92j78hckasfwykrrd1i2j3[...]
16.4224,96.8823,46.3238,68.1638,19.9932,61.6455,11.8039,24.5863 4x9v8y3effg6et3i529y94g[...]
32.2941,53.5815,57.2318,81.5036,16.7698,47.2962,19.7237,95.3329 t2k8hng1et85a8tvj255fcc[...]
[...]
The digits describe the location of the bounding box in the 4-dimensional space. The 10000 alphanumeric symbols after the space are the data.